De zéro à dashboard en 12 heures
Speed-run avec Claude Code. Monorepo 4 packages, WebSocket temps réel, 80 fichiers TypeScript. Le récit d un orchestrateur multi-projet construit en un weekend.
Le problème
Cinq terminaux, cinq sessions Claude Code, cinq projets en parallèle. Je perdais plus de temps à chercher quel terminal avait quel contexte qu’à réfléchir au code. Le dimanche soir, après avoir accidentellement fermé un terminal avec 45 minutes de contexte Claude dedans, j’ai décidé que ça suffisait.
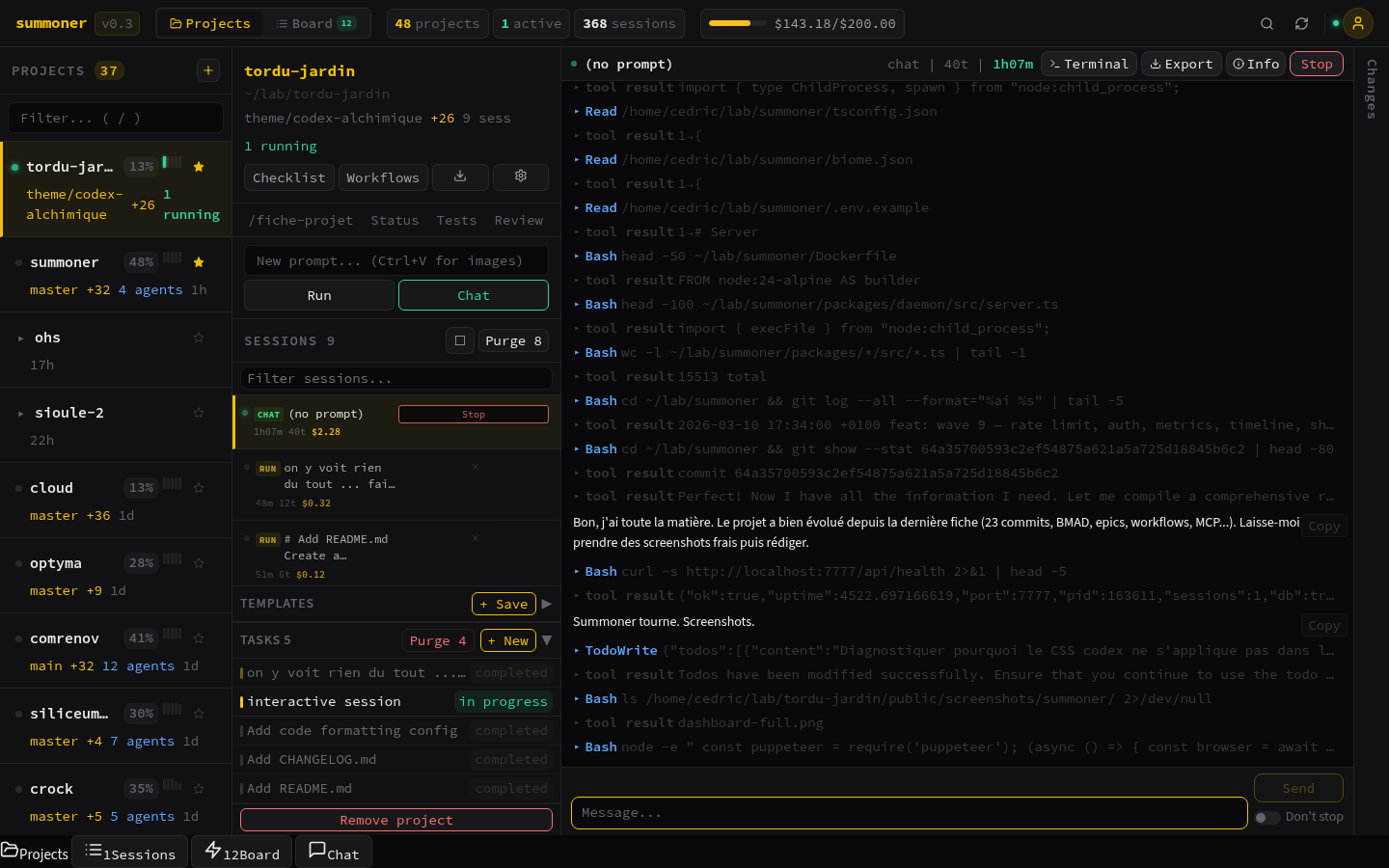
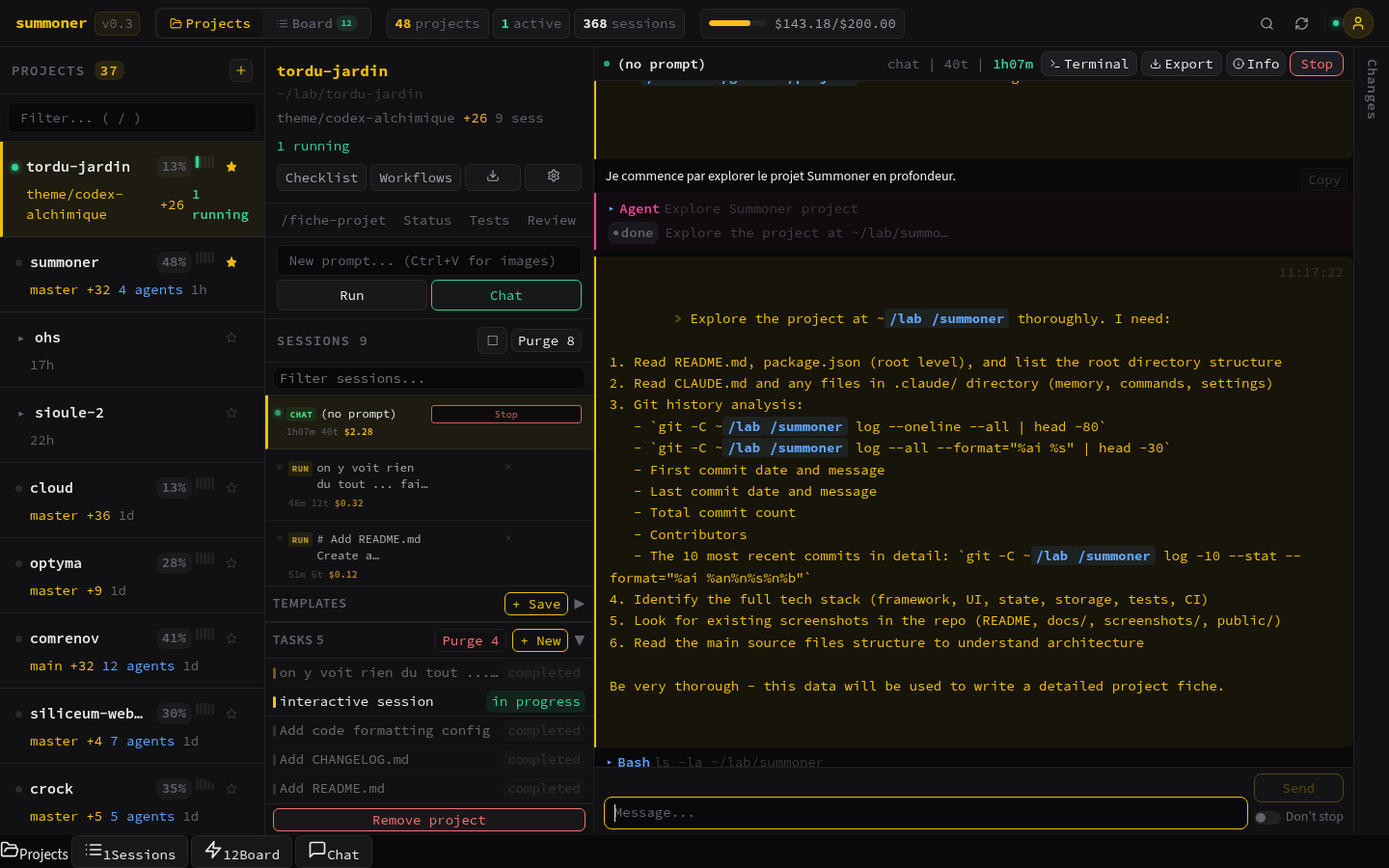
Il me fallait un control center. Un seul onglet navigateur pour voir tous mes projets, lancer des sessions Claude, suivre leur output en temps réel, et surtout ne jamais perdre un contexte. L’ironie du truc : je voulais construire cet outil avec Claude Code lui-même. L’orchestrateur qui orchestre son propre orchestrateur.
Le pari : un weekend. Du scaffold au dashboard fonctionnel. J’ai collé 10 waves sur un post-it et je me suis lancé.
Le plan en 10 waves
Avant de taper la moindre ligne de code, j’ai décrit les 10 étapes sur un post-it physique. Pas un Notion, pas un Jira - un post-it. Le genre de truc qu’on peut barrer au marqueur avec satisfaction.
- Scaffold monorepo + TypeScript strict
- Session manager avec node-pty
- API REST Fastify
- WebSocket temps réel
- Dashboard 3 colonnes (projets, sessions, chat)
- Kanban board
- Task queue + loop engine
- Auth + rate limit + metrics
- Raccourcis clavier
- Deploy
Premier commit à 16h48. Dernier commit de la journée à 23h43. Sept heures de travail effectif, plus les pauses café et les moments où je fixais l’écran en me demandant si j’étais en train de construire un monstre.
Choix de stack
La question React vs le reste s’est posée pendant exactement vingt minutes. Pour 22 composants sans routing complexe, sans state management global, sans SSR - React était une massue pour enfoncer un clou. J’ai choisi Lit 3. Six kilooctets. Web components natifs. Shadow DOM. Zéro framework overhead.
Le backend, c’était Fastify sans hésitation. Je l’avais déjà utilisé sur Où-est-mon-doc, je savais bootstrapper un serveur en dix minutes avec WebSocket intégré. SQLite en WAL mode pour la persistence - un fichier unique, zéro config, lectures concurrentes gratuites.
Le vrai choix technique, celui qui a conditionné tout le reste, c’était node-pty. C’est la seule manière fiable de spawner un process Claude CLI et de capturer son output en streaming. Pas un child_process.spawn, pas un exec - un vrai pseudo-terminal qui se comporte comme si quelqu’un tapait dans un shell.
const pty = spawn('claude', ['--output-format', 'stream-json', '--max-turns', '50', '-p', prompt], {
name: 'xterm-256color',
cols: 120,
rows: 40,
cwd: projectPath,
});Le parsing JSON qui m’a rendu fou
Le format --output-format stream-json de Claude CLI découpe les events en lignes JSON. Simple en théorie. En pratique, j’ai passé trois itérations à comprendre la structure réelle.
Premier piège : les tool_use ne sont pas au top-level de l’event. Ils sont enfouis dans message.content[], dans un tableau où chaque élément peut être du texte ou un tool call. Mon parser initial cherchait un champ tool_use à la racine et ne trouvait rien.
Deuxième piège : les longues lignes JSON sont coupées entre deux lectures du pipe. Un objet JSON de 8 Ko arrive en deux morceaux. La première moitié n’est pas du JSON valide. Mon JSON.parse() explosait en silence et je perdais des events.
La solution : un lineBuffer de 10 Mo max qui accumule les fragments et ne parse que quand il détecte un saut de ligne complet.
let lineBuffer = '';
const MAX_BUFFER = 10 * 1024 * 1024;
pty.onData((chunk: string) => {
lineBuffer += chunk;
if (lineBuffer.length > MAX_BUFFER) {
lineBuffer = lineBuffer.slice(-MAX_BUFFER);
}
const lines = lineBuffer.split('\n');
lineBuffer = lines.pop() || '';
for (const line of lines) {
if (!line.trim()) continue;
try {
const event = JSON.parse(line);
processStreamEvent(event);
} catch {
// Fragment incomplet, on ignore
}
}
});Trois heures pour arriver à ce code. Trois heures pour vingt lignes. C’est là le ratio réel du développement.
Les sessions zombies
Le deuxième caillou majeur. startOneshot() retournait la session immédiatement, avant que le process pty soit réellement spawné. Le code appelant recevait un objet session avec un statut “active” - sauf que le process n’existait pas encore. Résultat : des messages envoyés dans le vide, des WebSocket qui attendaient des réponses qui ne viendraient jamais.
J’ai ajouté un flag busy sur les sessions, un waitForSessionEnd() qui résout quand le process émet close, et un double-emit session:end sur error ET sur close pour couvrir tous les cas. Un ghost reaper tourne toutes les cinq minutes pour nettoyer les sessions orphelines - celles dont le process a crash sans émettre de signal propre.
C’est le genre de bug qui n’apparaît pas dans les tests unitaires. Il faut un vrai dashboard avec de vrais utilisateurs qui cliquent vite pour le voir. L’UI avait l’air de marcher, mais sous le capot, des sessions fantômes s’accumulaient et bouffaient de la mémoire.
Le WebSocket silencieux
Troisième surprise. Quand une session était occupée à traiter un prompt, les messages suivants étaient enfilés dans une queue côté serveur. Normal. Sauf que personne ne les envoyait jamais. L’utilisateur tapait un deuxième message, puis un troisième, et rien ne se passait. Pas d’erreur, pas de feedback - juste le silence.
La correction tenait en deux parties : une queue FIFO avec drain automatique quand la session repasse en idle, et un indicateur visuel “session busy” côté UI. Le genre de truc évident quand on le dit, invisible quand on code à 22h un dimanche.
Le monolithe assumé
Le server.ts du daemon fait 96 Ko dans un seul fichier. Toutes les routes Fastify, le WebSocket, le file serving, le CORS, l’auth - tout au même endroit. C’est un choix délibéré. Le premier jour, la priorité c’était la vitesse, pas l’architecture. Découper en modules propres, c’est le refactoring suivant.
Il y a une tension constante entre “faire bien” et “faire vite”. Ce projet était un speed-run. Le monolithe est le prix à payer pour un dashboard fonctionnel en douze heures. Je ne le regrette pas, mais je sais que le fichier va devoir être découpé avant d’ajouter la moindre feature supplémentaire.
Ce que Claude Code a fait vs ce que j’ai fait
Sur les 80 fichiers TypeScript, Claude en a généré environ 60 en première passe. Mais “générer” ne veut pas dire “terminer”. Chaque fichier a nécessité des ajustements : renommages, corrections de types, refactoring des imports, suppression de code mort.
Mon rôle était celui d’un architecte-revieweur. Je décrivais la structure voulue, Claude Code produisait le code, je testais, je corrigeais, je relançais. Le ratio approximatif : 30% de mon temps à décrire, 20% à reviewer, 50% à debugger ce qui ne marchait pas comme prévu.
La partie où Claude Code excelle : le boilerplate. Les routes CRUD, les types TypeScript, les web components avec leurs propriétés réactives. La partie où il galère : l’intégration. Faire marcher node-pty avec le stream JSON, gérer les edge cases du WebSocket, comprendre pourquoi une session spawne mais ne répond pas. Ça, c’est du debug humain.
Les 18 commits
Voici la timeline réelle du premier jour :
- 16h48 - Scaffold monorepo, trois packages, TypeScript strict partout
- 17h15 - Session manager fonctionnel, premier spawn de Claude CLI
- 17h52 - API REST basique, CRUD projets et sessions
- 18h30 - WebSocket temps réel, premier output de Claude dans le browser
- 19h10 - Dashboard 3 colonnes, CSS grid, premier rendu visuel
- 19h45 - Pause dîner. Le dashboard affiche du texte en temps réel. Moment de satisfaction.
- 20h20 - Syntax highlighting avec highlight.js, 11 langages
- 21h00 - Kanban board, drag-drop natif
- 21h40 - Task queue avec gestion de concurrence
- 22h15 - Loop engine pour les tâches récurrentes
- 22h50 - Auth bearer token, rate limit par IP
- 23h20 - Raccourcis clavier (j/k pour naviguer, Ctrl+K pour la palette)
- 23h43 - Dernier commit, nettoyage, le dashboard tourne
Dix-huit commits. Sept heures. Un monorepo fonctionnel avec session management, WebSocket temps réel, kanban, et une UI navigable au clavier.
Le lendemain
Le jour 2 a été consacré à l’enrichissement. Workflows YAML avec sept types d’étapes. BMAD orchestrator pour structurer les phases de travail. Blue-green deploy qui permet de redémarrer le daemon sans tuer les sessions actives - elles survivent au redeploy via un handoff sur un port secondaire.
Le jour 3, la project factory : une checklist de 46 items en 11 catégories pour auditer la santé d’un projet. Détection automatique de ce qui existe déjà (git hooks, Dockerfile, CI/CD, tests). Le MCP server qui expose les APIs Summoner comme outils pour Claude Code lui-même.
Ce que j’en retiens
Construire un outil complet en un weekend, c’est possible quand on connaît bien sa stack et qu’on a un plan précis. Les 10 waves sur le post-it m’ont évité de m’éparpiller. Claude Code a accéléré le boilerplate d’un facteur 5 ou 10, mais les bugs d’intégration restent des bugs d’intégration - il faut les comprendre soi-même.
Le vrai gain de productivité avec l’IA, ce n’est pas d’aller vite. C’est de pouvoir se concentrer sur l’architecture et les décisions pendant que quelqu’un d’autre tape le code répétitif. C’est un changement de posture, pas un changement de vitesse.
Summoner tourne maintenant en permanence sur ma machine. Un onglet, tous les projets, toutes les sessions. Le post-it est à la poubelle. Le problème est résolu.