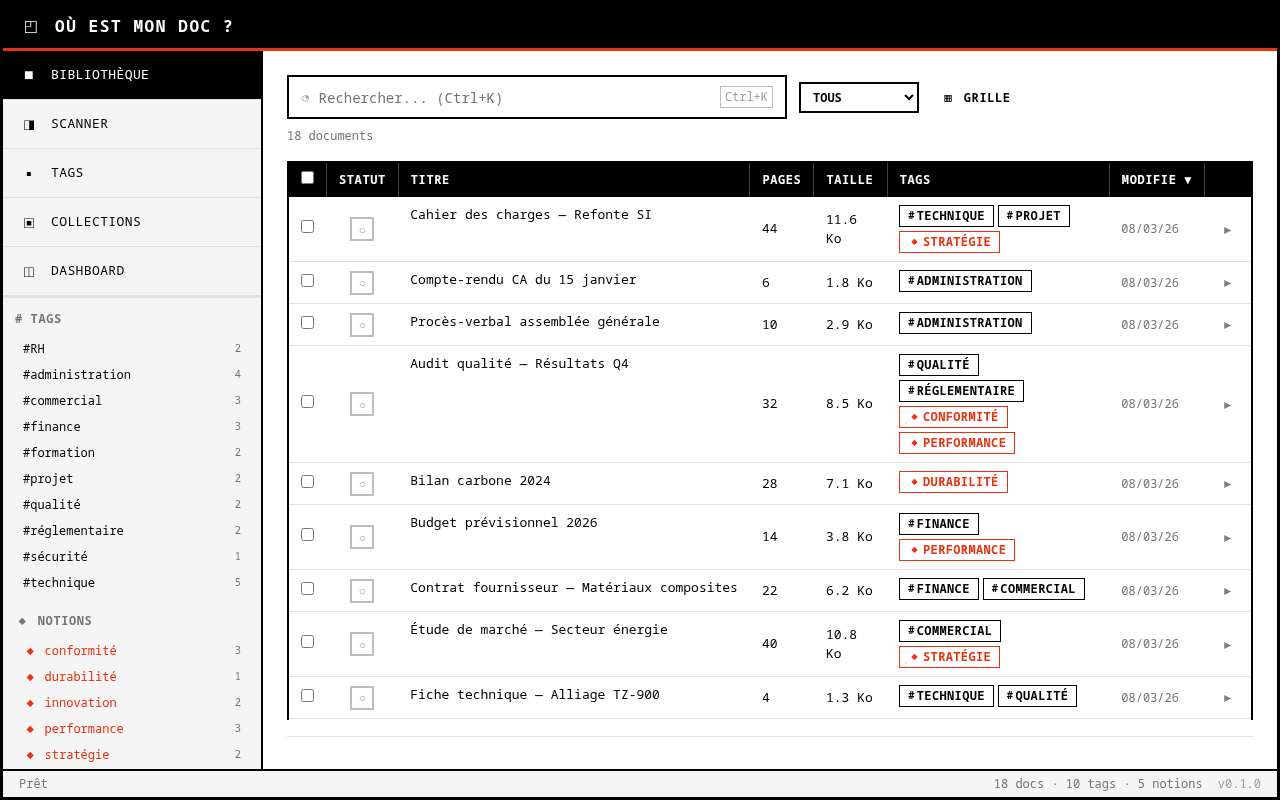
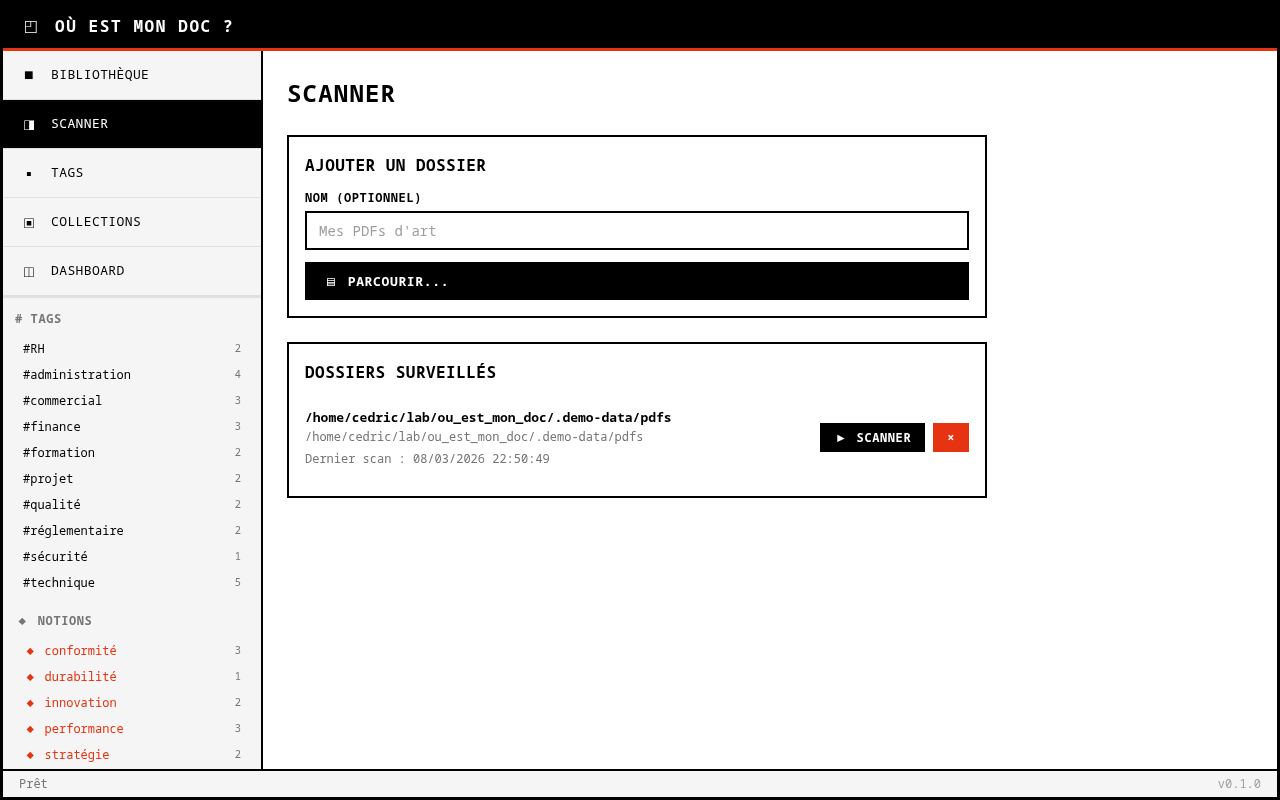
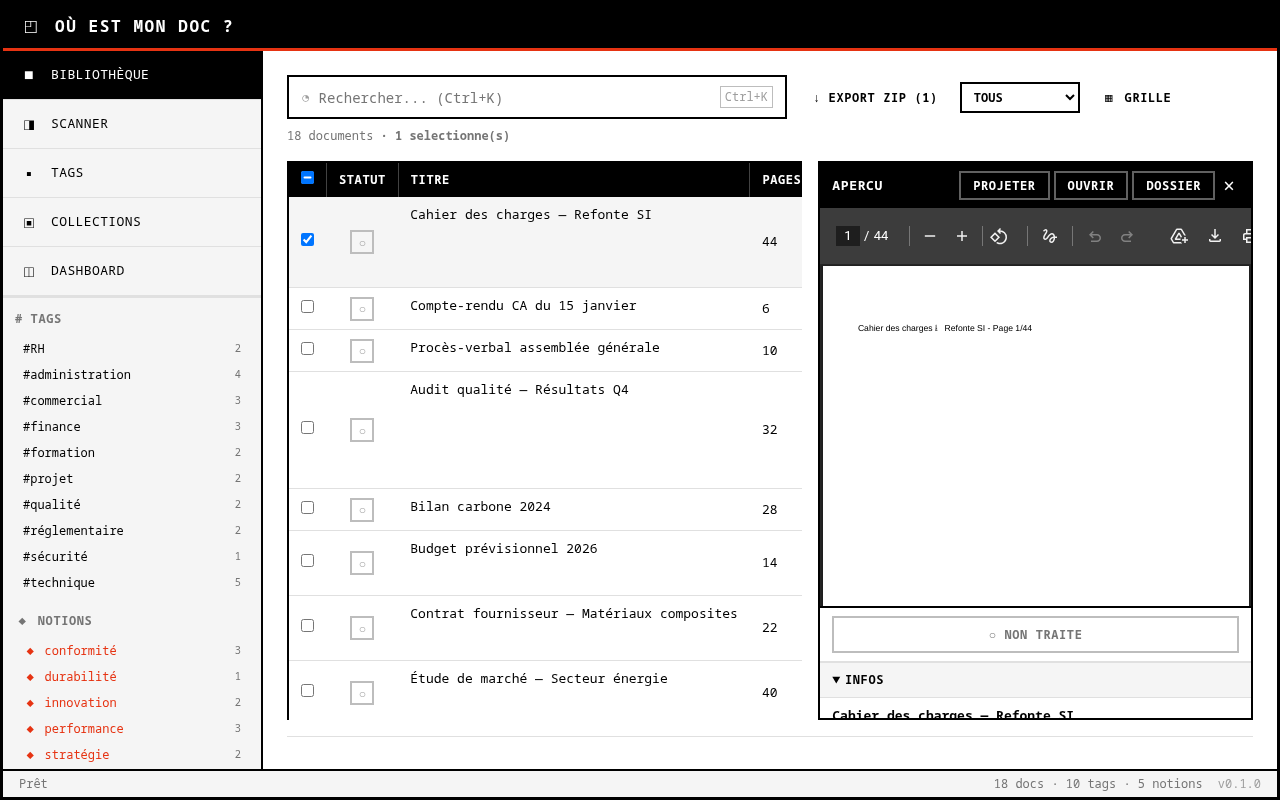
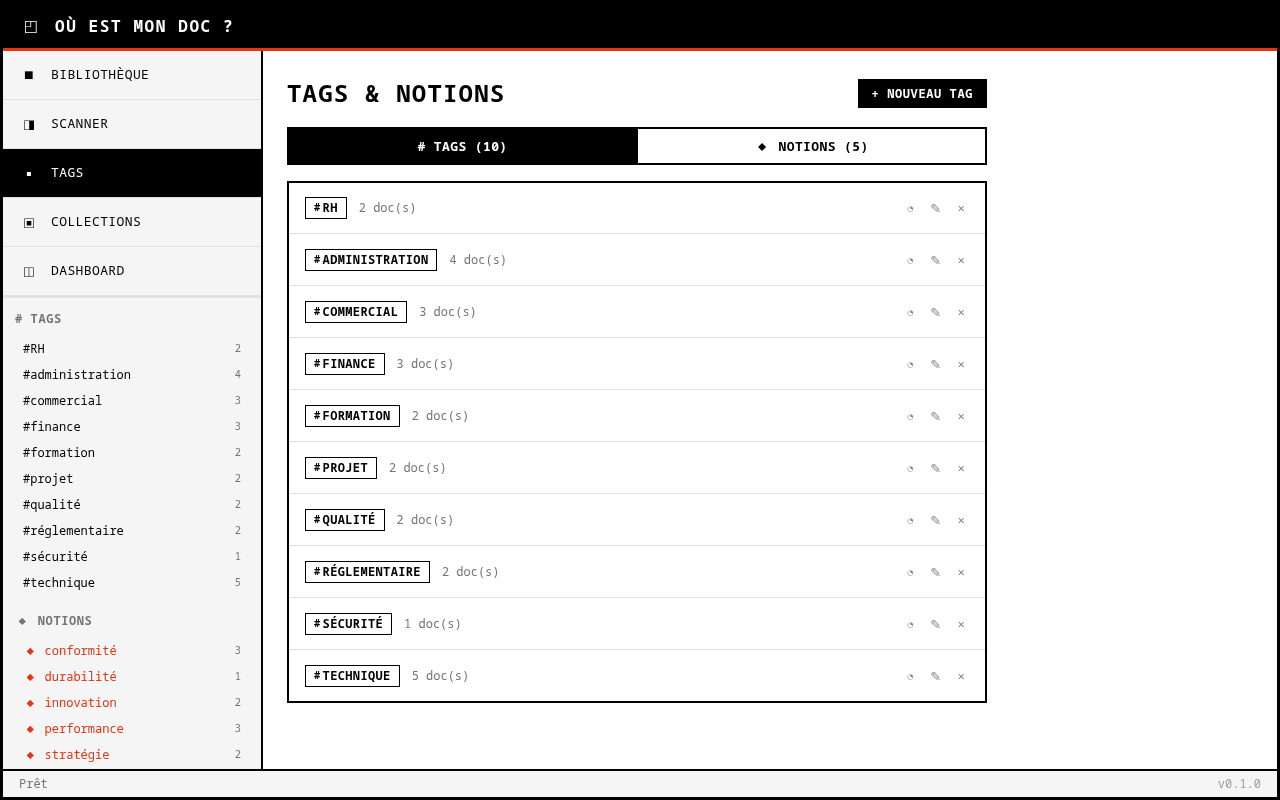
La genèse
Ma petite soeur est prof d’arts plastiques. Un jour, je la regarde préparer un cours. Elle a 47 onglets ouverts dans son explorateur de fichiers. Des PDF partout : fiches de séquences, reproductions d’oeuvres, consignes d’évaluation, documents officiels. Tout est rangé dans des dossiers par année, par niveau, par thème. Sauf que le rangement par dossier ne suffit plus quand un même document sert à trois séquences différentes. Elle cherche un PDF sur le clair-obscur, elle sait qu’il existe, elle l’a utilisé l’an dernier, mais impossible de le retrouver. Vingt minutes de navigation dans l’arborescence pour un fichier qu’elle ouvrira trente secondes.
Le problème n’est pas le stockage. C’est l’accès. Les fichiers sont là, bien présents sur le disque. Ce qu’il manque, c’est une couche d’intelligence par-dessus qui permette de retrouver un document par notion, par thème, par séquence, sans avoir à se souvenir dans quel dossier on l’a rangé il y a six mois.
L’approche
L’application ne copie jamais les fichiers. Elle référence les chemins sur disque et ajoute tags, notions et collections par-dessus le système de fichiers existant. Ma soeur garde son organisation, l’outil ajoute une surcouche. SQLite en raw SQL, sans ORM, une base dans un seul fichier. Le tout structuré en monorepo npm workspaces : un serveur Fastify pour l’API et le scanner, un client Vue pour l’interface, un package de types partagés, un packaging Tauri pour l’app desktop native en .deb, et un site de documentation dédié en Astro.
Le tournant LLM
Tagger 200 PDF à la main, personne ne le fera. L’ajout d’Ollama change la nature du projet. Le scanner ne se contente plus d’indexer les fichiers dans la base : il en extrait le contenu textuel et propose des tags automatiquement via un LLM qui tourne en local sur le CPU, sans cloud, sans envoi de données. Ma soeur pointe un dossier de 200 PDF et obtient une classification exploitable sans effort, sans lire chaque document. Et comme les documents pédagogiques peuvent contenir des travaux d’élèves, la confidentialité est un vrai sujet. Tout reste sur la machine. Comme Whisper, c’est de l’IA locale, privée, qui fait le travail sans poser de questions.
Comment ça marche
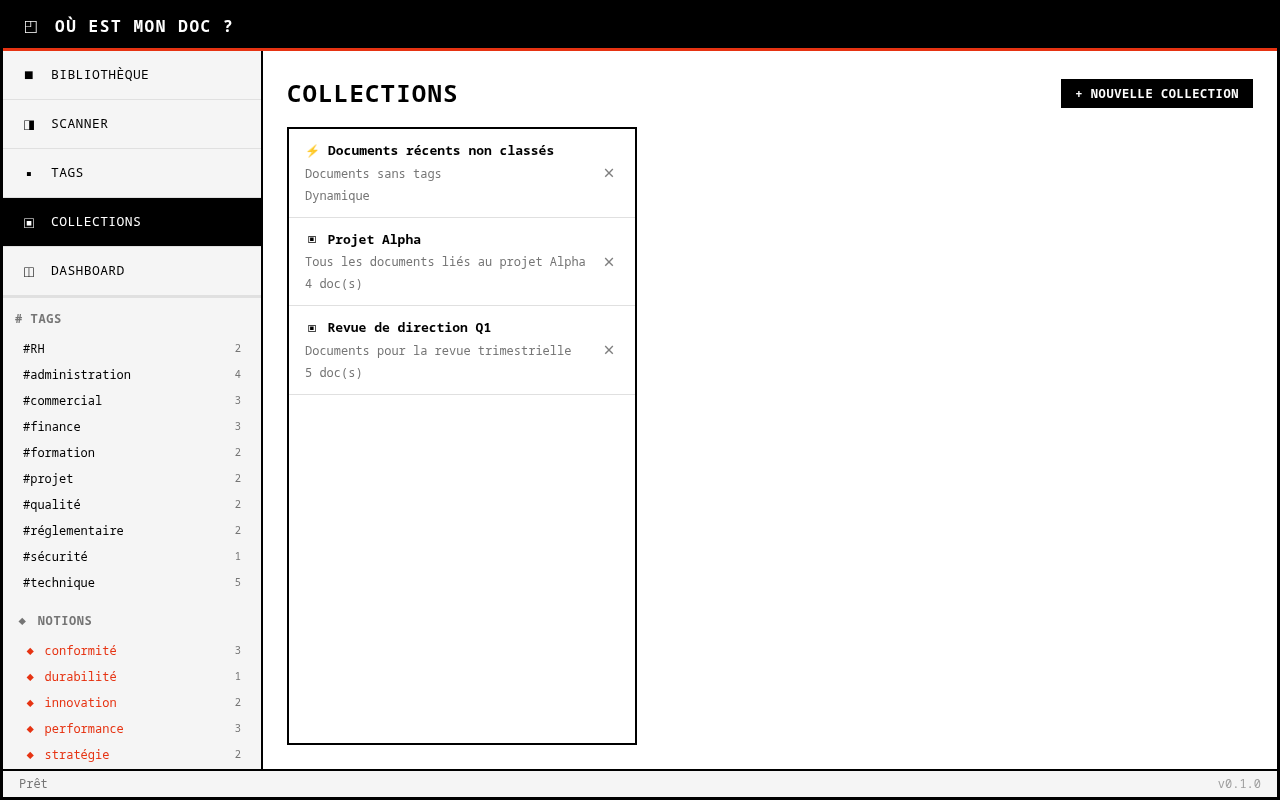
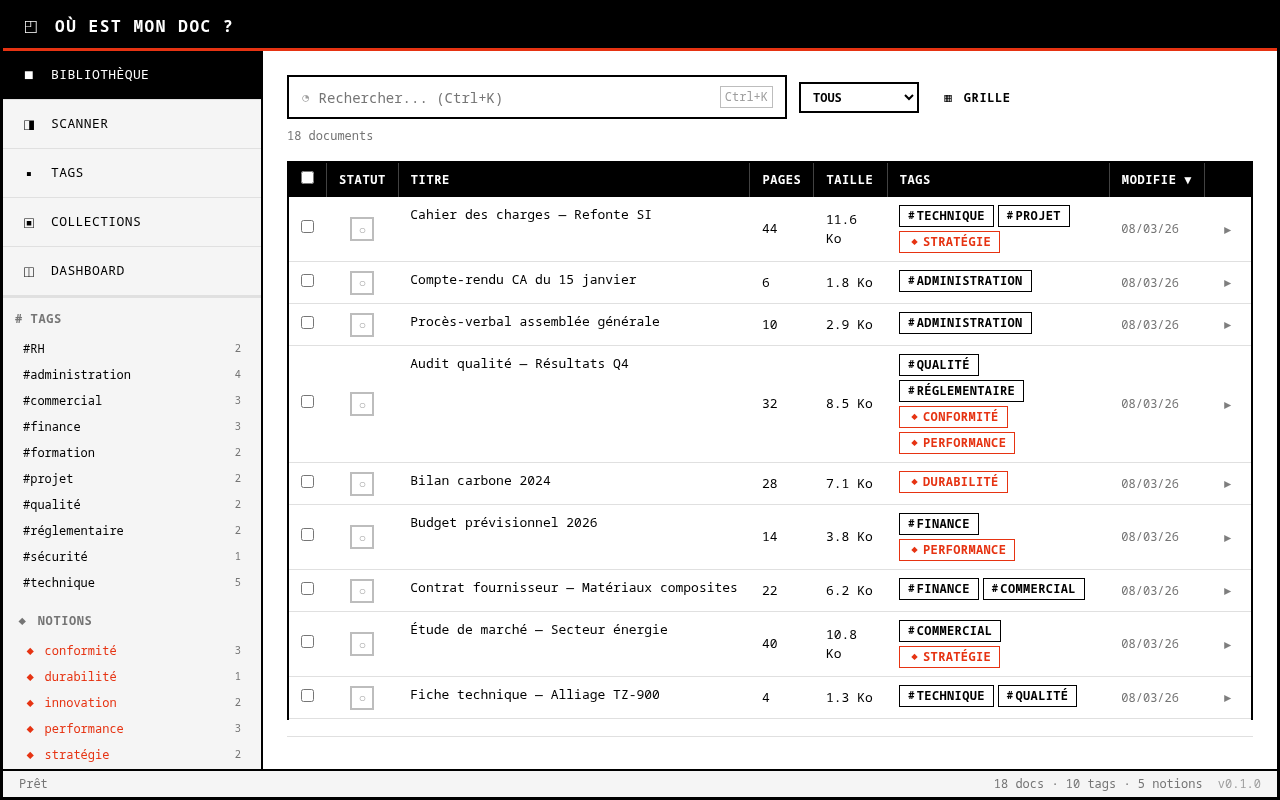
Ma soeur installe l’application sur son poste. Elle pointe le scanner vers ses dossiers de cours. L’outil parcourt récursivement l’arborescence, indexe chaque PDF, génère des miniatures en mosaïque 2x2, et propose des tags via Ollama. À partir de là, elle navigue par tags, par collections, par recherche. Un clic et le document s’ouvre.
En classe, elle passe en mode projection : texte agrandi, contraste maximal, interface dépouillée pour le vidéoprojecteur. Plus besoin de jongler entre 47 onglets. Elle peut aussi regrouper des documents dans des collections thématiques, exporter un lot en ZIP pour le partager avec des collègues. L’application se met à jour silencieusement avec un système de hot-update intégré, et le tout tourne comme une app desktop native via Tauri.
Design Bauhaus brutaliste
Zéro border-radius. Monospace. Noir, blanc, rouge. Ma soeur enseigne les arts plastiques, l’outil devait avoir une identité visuelle qui lui parle. Le Bauhaus, c’est son univers : l’intersection entre art et fonctionnalité. C’est un parti pris esthétique radical, à l’opposé du “Soft Minimal” de Totem, mais tout aussi cohérent et opinionnée. Pensé pour être lisible avant d’être joli.
Stats
| Durée | ~1 mois |
| Routes API | 10 |
| Vues frontend | 7 |
| URL | mondoc.tordu-jardin.fr |