Le dossier aux centaines de PDF
Une prof d arts plastiques, des centaines de PDF pédagogiques, et un explorateur de fichiers qui ne suffit plus. L histoire de « Où est mon doc ? »
La prof
Ma petite soeur est prof d’arts plastiques. Après des années d’enseignement, son disque dur déborde de documents pédagogiques : reproductions d’oeuvres, fiches de séquences, sujets d’évaluation, documents de référence. Tout en PDF, réparti dans une arborescence de dossiers qui ne fait sens que pour elle.
Pour retrouver un document, elle ouvre l’explorateur de fichiers et fouille. Dossier par dossier, sous-dossier par sous-dossier. Quand elle cherche un document sur le clair-obscur pour sa classe de troisième, ça peut prendre dix minutes. Dix minutes de cours perdues, ou dix minutes de préparation gaspillées.
Le dimanche du prototype
Un dimanche, je l’observe chercher un document. Naviguer dans l’arborescence, ouvrir un mauvais dossier, revenir en arrière, ouvrir un autre, tomber sur un fichier au nom cryptique, l’ouvrir pour vérifier, ce n’est pas le bon, recommencer.
Et si elle tapait « clair-obscur 3e » et que le bon document apparaissait ?
Les contraintes
Avant d’écrire une ligne de code, les contraintes étaient claires :
- Local. Pas de cloud, pas de serveur distant, pas de compte à créer. Les documents pédagogiques restent sur le poste. L’application ne copie rien, elle référence les chemins sur disque et ajoute des métadonnées par-dessus.
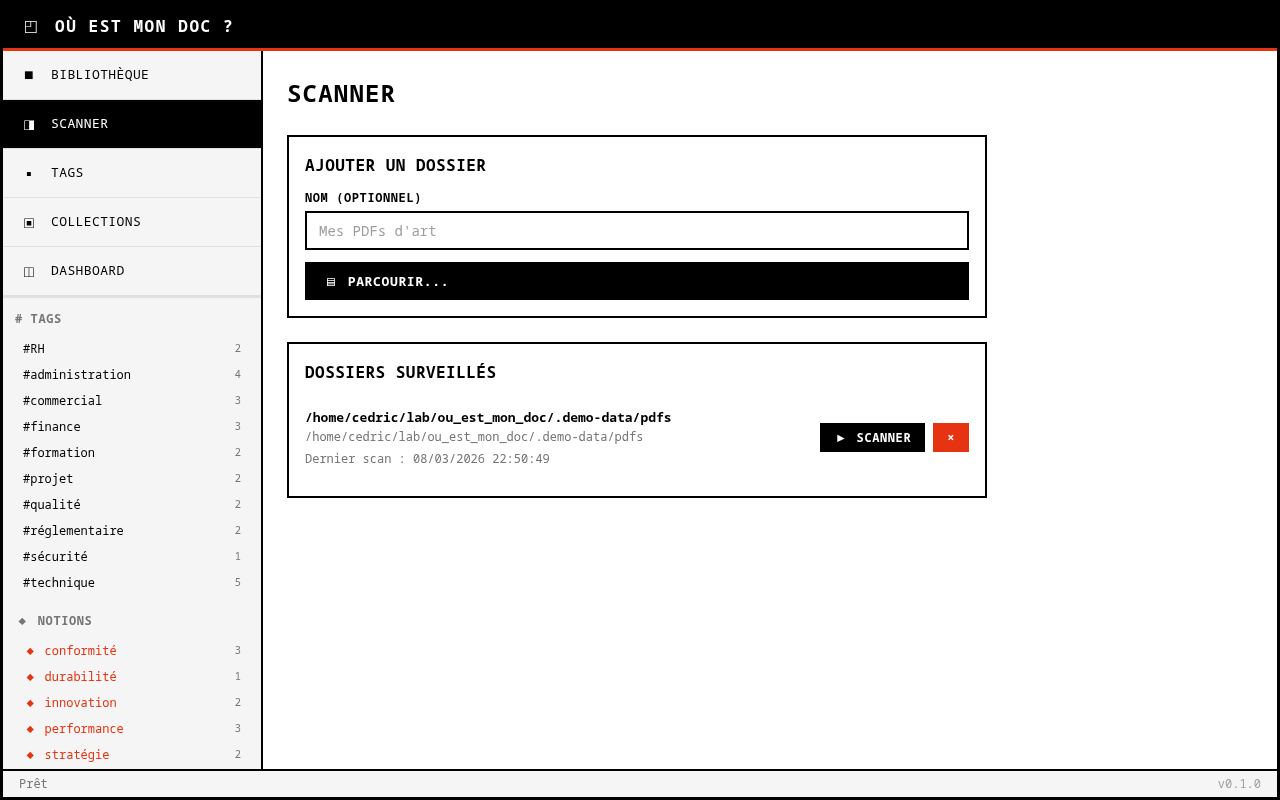
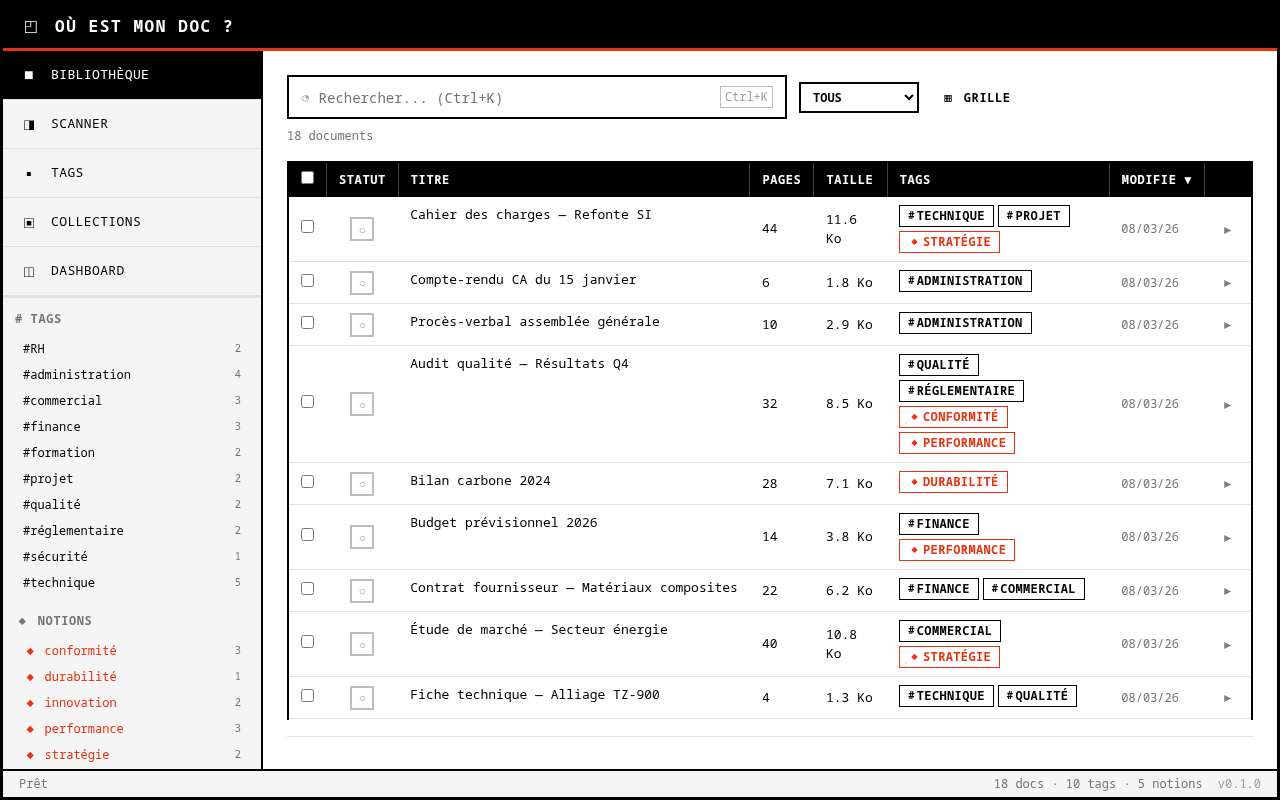
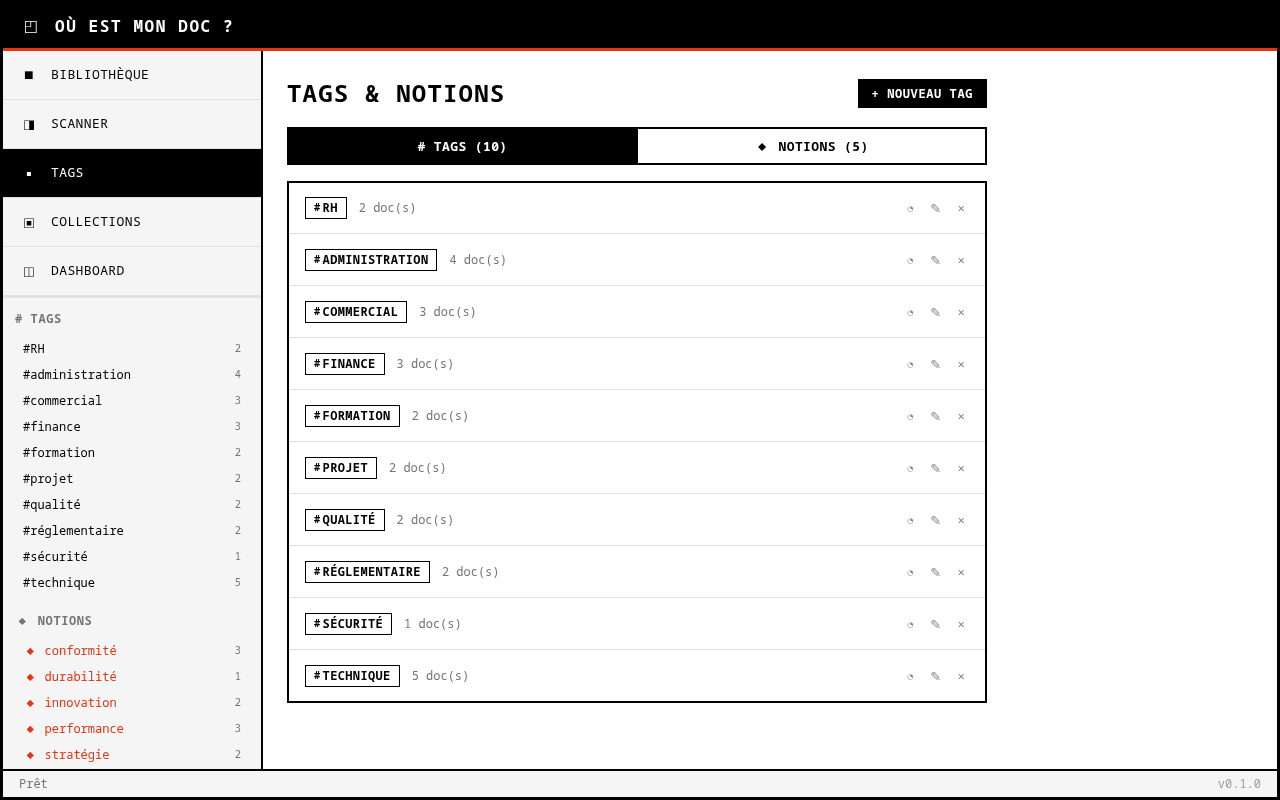
- Simple. Un scanner de dossiers, une bibliothèque, des tags, des collections. Un clic pour ouvrir le document.
- Intelligente. Pas juste une recherche par nom de fichier. Un LLM local qui extrait le contenu des PDF et propose des tags automatiquement.
- Offline. La connexion Internet dans les établissements scolaires n’est pas toujours fiable.
La stack
Vue 3.5 en frontend, Fastify 5 en backend pour l’API et le scanner, SQLite en raw SQL pour la persistence, Tauri 2 pour emballer le tout en application desktop native. Et Ollama pour faire tourner un LLM en local.
C’est un monorepo npm workspaces avec 3 packages (server, client, shared) plus Tauri et un site doc Astro. 10 routes API, 7 vues frontend. Le tout co-authored à 40% avec Claude Code.
Le tournant Ollama
Le scanner de dossiers parcourt récursivement un répertoire et indexe tous les PDF. C’est le minimum. Le vrai saut, c’est quand Ollama entre en jeu. Le serveur extrait le contenu textuel de chaque PDF et le soumet au LLM local pour proposer des tags automatiquement.
Un dossier entier se retrouve classé sans effort humain, sans rien envoyer sur Internet. Le modèle tourne sur le CPU. C’est plus lent qu’un appel API cloud, mais la confidentialité n’est pas négociable quand on gère des documents scolaires.
Le design Bauhaus
L’identité visuelle est à l’opposé du « Soft Minimal » de Totem. Zéro border-radius. Typographie monospace. Noir, blanc, rouge. Le Bauhaus comme principe : la forme suit la fonction.
Le mode projection, pensé pour la salle de classe, pousse cette logique encore plus loin. Texte agrandi, contraste maximal, navigation simplifiée. Un prof devant ses élèves n’a pas le temps de chercher un bouton.
La réaction
Quand j’ai montré l’outil, elle a scanné son dossier de travail et trouvé un document qu’elle cherchait depuis des semaines. En deux clics. Sa réaction : « Mais pourquoi ça n’existe pas déjà ? »
C’est la meilleure validation qu’un projet puisse recevoir. Pas un benchmark, pas un test A/B, juste quelqu’un qui retrouve un document perdu et qui sourit.
Ce que j’en retiens
Le meilleur brief produit, c’est observer quelqu’un galérer. Pas un ticket Jira, pas une user story, juste l’observation silencieuse d’une vraie personne qui fait un vrai travail avec un outil inadapté.
Où-est-mon-doc n’est pas un produit. C’est un outil pour une personne. 15 commits, 10 routes API, 7 vues. Pas plus que ce qu’il faut. Et c’est peut-être la forme la plus pure du développement : résoudre un problème concret pour quelqu’un qu’on connaît.